CSV vs Parquet vs JSON
CSV, Parquet or JSON. When to use what format and the pros and cons of each.
8 min read

Data in the real world is born in different forms, times, and places. The form can dictate how you query it and how fast your analysis will take sometimes.
Let's dive into what data formats there are and the pros and cons of each. There are a lot of data formats out there, but here is a pretty big list:
- CSV
- JSON
- XML
- HTML
- Parquet
- ORC (Optimized Row Columnar)
- Excel
- Fixed-Width
- HDF (Hierarchical Data Format)
We are going to focus on the most popular data formats out there which are CSV, Parquet, and JSON. Each one of these is great in its own way, so it's important to know how each one can be useful to you and your analysis. There aren't a lot of tools that can read these formats, but luckily there are a few like BitRook that can read them.
CSV
Let's start with Mr. Popularity - CSV or Comma Separated Values. Just a fancy way of saying a text file with values separated by a comma (sometimes other delimiters) and usually each row of data separated by a new line. First came out in 1972 and grew in popularity over time. CSV has some oddities to it and is pretty complex.
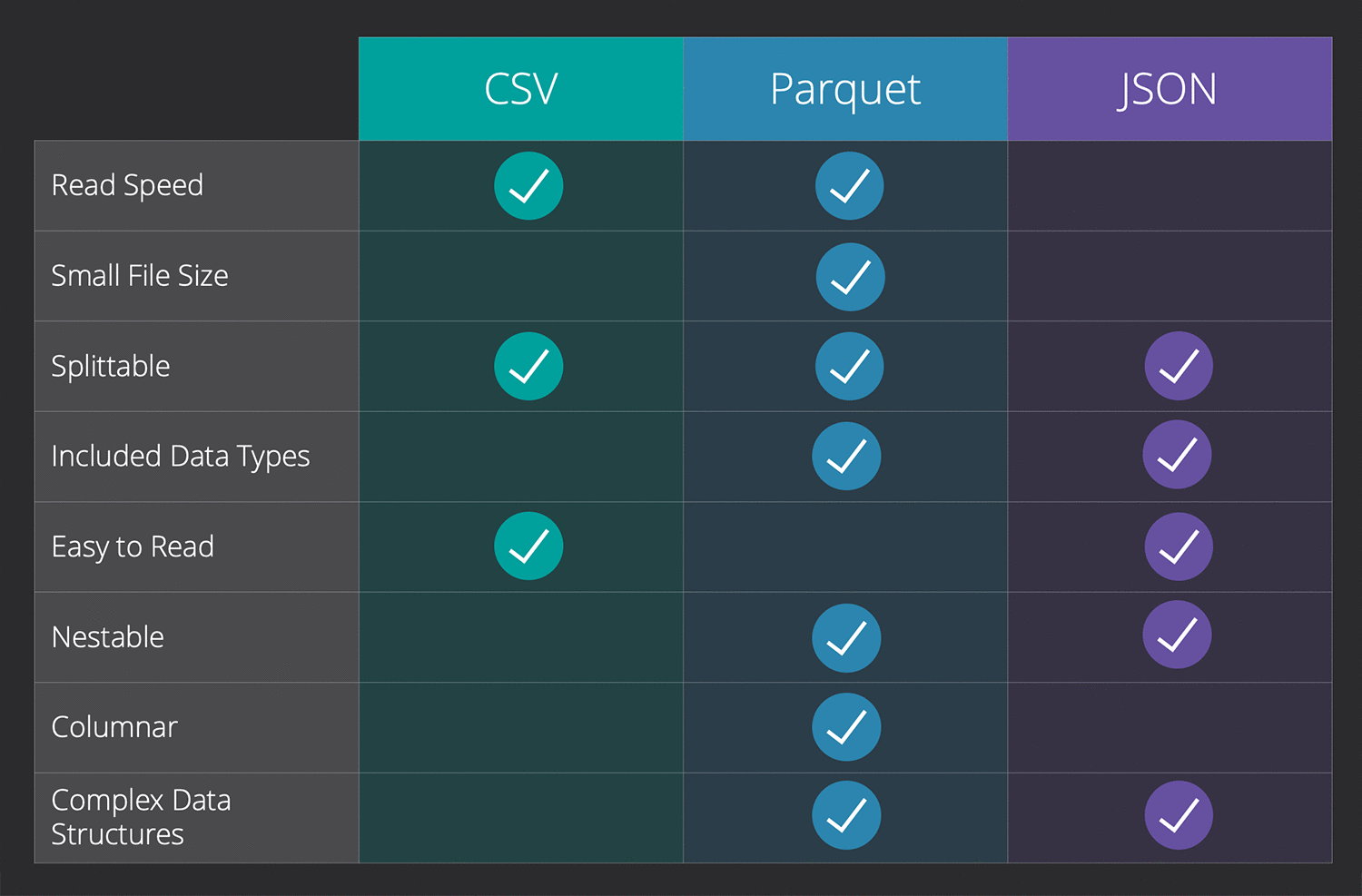
Read Speed
CSV is fairly quick to read, but when you start getting quite large either in the number of records (vertically) or the number of columns (horizontally) then it gets quite slow. There are a lot of articles on how to speed up reading (choosing a few columns, setting dtypes, dask, and more).
File Size
CSV is fairly compact because each record's data point is only stated once at the top as a header. CSV can also be compressed incredibly well. That being said there are smaller formats.
Splittable
One way to deal with large datasets is to split them up into smaller ones. This usually means less memory is needed to process the file. Luckily CSV is easy to split with Pandas or even easier with BitRook.
Included Data Types
Some data formats have the column names and the type of data baked into the file. This is where CSV can be troublesome. Tools like pandas and even more so BitRook can try to determine the type of each column, but it's never as precise and validated as some other data types like parquet.
Easy to Read
Sometimes you just need to peek inside a file and see the structure, columns, missing data, and everything else. CSV is incredibly easy to read since almost every program can read it. It's the most universal format. This is CSV's biggest strength - easy to read for humans and any application.
Nestable
Nestable data means that a column can hold more than just a data type inside, possibly a list of something or even hierarchical data to other data. CSV cannot do this out of the box, typically you have to provide an ID that relates to another CSV file. While it works, it makes for some messy data analysis work.
Columnar
This could be a strength or a weakness, it depends on the type of analysis you are doing. More and more databases are moving to a columnar type database because it is considered faster in most use cases. Some data formats are set up to be columnar out of the box. CSV is row-based and not columnar.
Complex Data Structures
There are typical types of data (int, string, DateTime) and then there are complex data types (structs, arrays, and maps). Some data formats have this as an available feature, but CSV does not have these complex data types. You will need to do extra work to turn a column that contains a list of values into something useable.
Pros
- Universal, easy to use in any application
- Easy to read
- Compresses well
Cons
- No data types included, usually requires extra effort
- Moderately slow to read
- Can't include nestable data or complex data types
- Fairly large file size
JSON
JSON or JavaScript Object Notation is an open data format and is widely used by APIs (Application Programming Interface - basically how servers talk to each other) and several databases (like MongoDB). It's small and powerful when compared to previous formats developers used like XML.
Read Speed
Generally, JSON is loaded completely into memory, and then you can analyze it. This is mostly due to the data structure. This makes it much slower to read in large JSON files.
Small File Size
While JSON is a lot smaller compared to XML, it's quite large in file size compared to CSV or some other formats. Mostly because it includes the column/attribute name over and over again.
Splittable
JSON files are splittable, but not easily done like CSV files. Mostly due to the fact that you usually have to parse and load the whole file to split it.
Included Data Types
JSON does define strings (with quotes), numbers, objects, and lists differently. It doesn't necessarily define these data types, the data types are inferred when parsing the file. This generally works well and doesn't have too many issues.
Easy to Read
JSON is one of the easiest to read formats as long as you have formatted it. It can be compressed and even put on one line, but when it's formatted nicely it's a pleasure to read. There are plenty of online formatters and offline IDEs that can format JSON nicely, but BitRook does it best because it flattens the JSON and then shows you each element.
Nestable
This is where JSON shines above many formats, you can nest data deeply inside JSON and this is why it's great for unstructured data formats.
Columnar
JSON is an object notation and so it's in a sense row-based, not column-based. This makes it a little slower to work with.
Complex Data Structures
You can put complex data types inside JSON such as objects, lists, and much more.
Pros
- Great for nested or unstructured data
- Easy to read
Cons
- Typically have to load the entire file to read it
- Large file size when compared to CSV or Parquet
Parquet
Released in 2013 parquet is an open columnar data type that is common in big data environments and great for automated workflows and storage. If your team uses Hadoop then this is most likely their favorite format. Parquet is self-describing in that it includes metadata that includes the schema and structure of the file.
Read Speed
Parquet is one of the fastest file types to read generally and much faster than either JSON or CSV.
File Size
Parquet is known for being great for storage purposes because it's so small in file size and can save you money in a cloud environment. Parquet will be somewhere around 1/4 of the size of a CSV.
Splittable
Parquet is easily splittable and it's very common to have multiple parquet files that hold a dataset.
Included Data Types
Parquet shines uniquely here. Each column has a data type that it has to follow. This makes it easy to read and just start using and is great for automation because it reduces the need for code that parses the data types.
Easy to Read
Parquet is not easy to read generally. You have to use code to read it or use BitRook to read it easily. This is a big data format, not necessarily for people just starting.
Nestable
In parquet, you can nest some data inside each column and use some unique data types.
Columnar
Parquet is a columnar data format and because of this is much faster to work with and can be even faster if you only need some columns.
Complex Data Structures
Parquet can handle complex data types (Int32, Timestamp, and more). If you have a dataset where you have specific data types you need to be precise - this is a data format to look at.
Pros
- Data Types are set automatically and enforced
- Small file size
- Read speed is fantastic
- Nestable and complex data type handling
Cons
- Hard to read without code or BitRook
Summary
Clean Data 10x faster using AI with BitRook.
Download the app here for FREE.
We won't send you spam. Unsubscribe at any time.